Encontrado un contraejemplo de la conjetura jacobiana con Claude Fable 5
Ayer, día 19 de julio de 2026, fue un día grandioso para España en lo que a fútbol se refiere, ya...
Leer más
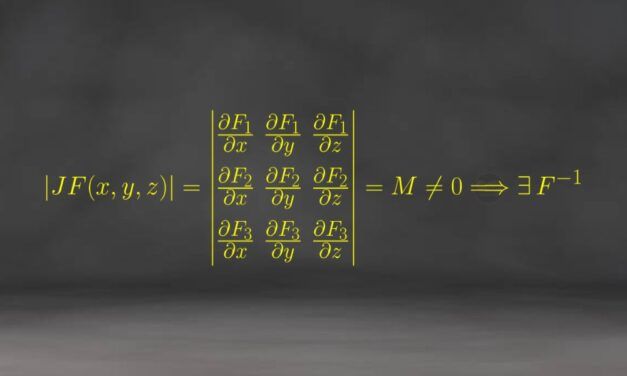
Ayer, día 19 de julio de 2026, fue un día grandioso para España en lo que a fútbol se refiere, ya...
Leer más
Hace ya unos años (en 2011, concretamente), escribía en el blog sobre la conocida como conjetura...
Leer más
Una de las ramas de las matemáticas más olvidadas (y menos estudiadas en la actualidad en niveles...
Leer más
Todos los que habitualmente pasáis por aquí conocéis el factorial, que aplicado a los naturales...
Leer más
Si lees la frase “el número de días de julio”, ¿qué te viene a la cabeza? Posiblemente, el número...
Leer más
Sin lugar a dudas, es uno de los «mantras» matemáticos por excelencia: «menos» por «menos» es...
Leer más
Sabéis que hay ciertos temas que nos gustan mucho en este blog, y las demostraciones de...
Leer más
Los números perfectos son un conjunto de números que podríamos llamar «icónicos» dentro de las...
Leer más
La pasada semana, hablábamos en la entrada Cómo usar una parábola para multiplicar dos números...
Leer más
El algoritmo de la multiplicación de dos números enteros positivos es, como todos sabemos, un...
Leer más
Parece que esta semana en Gaussianos la cosa va de «nuevas demostraciones» de teoremas famosos. En...
Leer más
Desde hace unos días, llevo viendo en distintos sitios de internet la noticia de que dos...
Leer más
Gaussianos recibió el Premio Prisma 2018 a la mejor web/red social. Haz click en la imagen si quieres saber más.

Los Premios Prismas son una iniciativa de los Museos Científicos Coruñeses para premiar la difusión de la cultura científica y apoyar a profesionales que trabajan en este campo. Más información en Premios Prismas.
Si quieres recibir los artículos de Gaussianos en tu mail, haz click en la imagen.

Únete a la iniciativa Yo construí el poliedro de Császár. Haz click en la imagen para conocer todo los detalles.

Y visita este set de Flickr para ver las construcciones de los lectores de Gaussianos.
Últimos comentarios